1. [50%]Synthesis of deceptive strategies in reachability games with action misperception
Abhishek N. Kulkarni et al., IJCAI 2020
- Main problem to solve: two player (P1, P2) plays a turn-based game, P2 knows part of P1’s action and try to prevent P1 from reaching the goal. P1和P2轮流进行游戏。 P1的目标是达到目的地,P2的目的是阻止P1达成目标。开始阶段P2只知道部分P1的action,P1方设法利用P2的信息不完善取得优势,P2则在交互中发现未知的P1的action。
- hyper game [Bennett 1977]
- DASW: Deceptive Almost-Sure Winning
1.1. Game on graph
- Action sets of P1 and P2 be
and . A turn-based game on graph is the tuple: , where is the set of states partitioned into P1’s state and P2’s satates . P1 chooses an action when and P2 chooses an action when . is set of action for P1 and P2. is a deterministic transition function that maps a state and an action to a successor state. is a set of final states.
is the -th state-action pair. is from step to step . is a run (state-history) is the action-history - reachability objectives:
怎么理解里面的等式? 整个过程中曾经出现过的state,若 ,则P1赢(final states出现在过程中),否则P2赢。 - Zielonka’s Algorithm
- Concurrent reachability games
Example here
- P1 state
, P2 state - The objective for P1 is to reach the final state
from the initial state - P1 action
, P2 action 
1.2. Action misperception and information asymmetry
- P1 has complete information about
and . (Misperceives) P1’s action set is . P1知道所有可能的action ,但是其只能执行 的一部分 。 P2 only konws P2只知道它自己可以执行的action ,通过观察逐步得知 中的action。 Both P1 and P2 have complete information about the game state-space , transition function and the final states . - P1’s perceptual game is identical to the ground-truth game:
P2’s peceptual game is a game under misperception: - P1 will compute a conservative strategy, because she assume P2 will react to all
(P2 has extra strategy for ) P1认为P2针对 以外但属于 的action有额外的策略,因此会采取保守策略。 - Other questions:
- P2 observes P1 playing an action
, which P2 did not believe to be in P1’s action set? P2观察到P1执行了其不知道的action,将其加入自己的perceived action set 。 - P2 might be capable of complex inference by observing P1 can perform an action
, infer that P1 must be capable of action and . P2可以进行推理,若action 由 和 两步构成,则推测出更多P1可以执行的action 。
- P2 observes P1 playing an action
2. [30%]Secure-by-synthesis network with active deception and temporal logic specifications
Jie Fu et al., Arxiv 2020
-
Main idea: a deterministic, turn-based game arena
-
The limitation of attack graphs: They do not take into account the possible defense mechanisms that can be used online by a security system during an active attack.
-
Check
Stackelberg games, Nash games, Bayesian games. -
Game graph of the individual games being played by the attacker and defender:
- A transition system, called arena, which captures all possible interactions over multiple stages of the game.
- A labeling function that related an outcome-a sequence of states in the game graph-to properties specified in logic.
- The temporal logic specifications as the players’ Boolean objectives.
-
Attack graph: Network conditions, (attacker and defender’s) own states, and transition function that captures the pre- and post-conditions of actions given states.
- A pre-condition: a logical formula that needs to be satisfied for an action to be taken.
- A post-condition: a logical formula describes the effect of an action in the network system.
2.1. Turn-based game arena tuple
(resp., ) is the set of actions of P1 (resp., P2) is a dterministic transition function that maps a state-action pair to a next state is the set of atomic propositions. is the labeling function that maps each state to a set
2.2. Payoffs
Linear temporal logic
-
next -
Until -
Level-1 vs. level-2
- Level-1: A two-player hypergame, a pair
- Level-2: A two-player hypergame, a pair
P1 perceives the interaction as a level-1 hypergame and P2 perceives the interaction as game . P1能观察并和整个游戏交互,P2只能观察/交互其中的一部分。
- Level-1: A two-player hypergame, a pair
3. [50%]A receding-horizon MDP approach for performance evaluation of moving target defense in networks
Zhentian Qian et al., Arxiv 2020
| 项目 | 解释 | |
| 环境/游戏类型 | 回合(题设) | 多回合 |
| Follower/attacker | 知识(题设) | 每回合开始时更新MDP,会侦测到defender布置的IDS(以一定正确概率) |
| 策略(题设) | 0. 侦测当前states 1. 对attacker用基于MDP的PAG建模 2. 在模型的基础上通过risk-sensitive finite-horizon planning和Iterative re-plan the attack strategy using a receding horizon framework选择此回合的策略 | |
| Defender/leader | 知识(题设) | 本文中没有关于attacker的相关知识 |
| 策略 | 随机在MDP的状态中布置IDS,调整的参量为IDS的数量或IDS位置的重新分布频率 | |
-
Main work: 先对attacker建模,将模型应用于设定场景中,再通过改变defender的变量,衡量场景中不同defender参数的效果。
- Understand how the attacker behaves given the uncertainty:
Attacker将实时检测并重新规划抵达目标的路径以避免被发现(repeatedly perform reconnaissance to learn about the locations of intrusion detection systems and re-plan optimally to reach the target while avoiding detection)
在uncertainty下如何对attacker建模,分为两步:
- Model the network with dynamic defense as a time-varying probabilistic attack graph, which is an MDP with time-varying probabilistic transition function and reward function.
模型基于MDP,probabilistic transition function和reward function是随时间变化的。
用PAG(probabilistic attack graph)建立graphical security model。
此MDP中何为probabilistic:
的几率成功转移到下一状态 , 的几率转移失败留在现状态 。 - Solve the attack strategy using
- Risk-sensitive finite-horizon planning
- Iterative re-plan the attack strategy using a receding horizon framework.
- Model the network with dynamic defense as a time-varying probabilistic attack graph, which is an MDP with time-varying probabilistic transition function and reward function.
模型基于MDP,probabilistic transition function和reward function是随时间变化的。
用PAG(probabilistic attack graph)建立graphical security model。
此MDP中何为probabilistic:
- 衡量defender strategy的标准:probability of successful and stealthy attack。 变量: 1. IDS的数量。 2. IDS shuffle的频率。
- Understand how the attacker behaves given the uncertainty:
Attacker将实时检测并重新规划抵达目标的路径以避免被发现(repeatedly perform reconnaissance to learn about the locations of intrusion detection systems and re-plan optimally to reach the target while avoiding detection)
在uncertainty下如何对attacker建模,分为两步:
-
一般使用IDS (Intrusion Detection System)的策略:通常defender并不知道attacker是否存在,只是布置pre-defined security protocols。(固定位置/随机位置) 研究问题:如何评估proactive defense strategy在attacker攻击成功之前检测到attacker的效力?
-
Security model类型:
- attack graphs
- attack-defence trees
- probabilistic attack graphs for Moving Target Defense (MTD)
Method
-
Problem formulation:
- The attacker may success with
, or fail with (PAG/Probabilistic Attack Graph). - The defender randomly select some nodes for IDS (with some distribution, also depends on time
). - The attacker knows PAG, does not know how defender arrange the IDS (actual deployment).
- The attacker can scan for IDS (observation of the deployment).
- The attacker may success with
-
Attacker’s behavior modeling:
- Risk-sensitive planning:
- 某个policy的期望价值的直观理解:
,discount只对immediate reward应用一次(与RL有所区别)? - 最优policy应最大化
- Primal Linear Program:对于以任意状态起始,最小化总的预期收益(每个起始状态概率乘以从此状态开始能获得的最大预期收益)?
- Dual Linear Program:
- 某个policy的期望价值的直观理解:
- Receding-horizon attack planning:
- 何时attacker被IDS所捕获;捕获后结果:
- Attacker应尽量避开IDS(当作障碍)。We treat these nodes (equipped with IDSs) as obstacles which the attacker is to avoid.
- “sink”: an absorbing states with zero reward
- 若状态
存在可转移的下一状态 ( ),且 布置了IDS( ),那么attacker会陷入sink state。 When attacker exploits a vulnerability that has a positive probability to reach a node with IDS, then it will reach a sink state with probability one- that is, it is detected
- Attacker如何应对:
- 若attacker总是知道IDS的布置,可以doing nothing或者攻击没有IDS的host
- 若IDS随机布置,应用本文算法1
- 假设attacker knows exactly the sequence of locations for IDSs sampled over its planning horizon
- 本文的attack planning algorithm不能learn and predict the changes in the network。
- 何时attacker被IDS所捕获;捕获后结果:
- [待整理]MDP:
, is the initial state distribution. Immedediate reward function . is a constant for finite horizon length The terminal reward sink state: for , , if and , then . 下一个状态为IDS node时,不管攻击是否成功,均会被检测到。与此 对应的 - [待整理]
: expectation. 用对数的原因应该与 的分布,softmax Bellman operator,以及entropy-regulated optimal policy有关?Softmax: CMU课件 用Dual linear program进行优化 - [待整理]算法:
- 先进行netscan获取
,初始化新的MDP的具体参数(reward) - 对policy进行优化
- 根据优化后的policy执行一步action
- 系统判定是否被IDS侦测到
- 若未侦测到,则回到第一步,开始新的一个回合
- 先进行netscan获取
- Risk-sensitive planning:
ref to check:
- attack graph
- dynamic game models
4. [10%]Opportunicstic synthesis in reactive games under information asymmetry
Jie Fu, Allerton 2019 Abhishek N. Kulkarni et al., Arxiv 2019
- Main idea
: the robot (a controlled agent), : its adversary (an uncontrolled environment agent) - Deterministic finite automaton (DFA):
: the set of states : the set of input symbols, is the set of atomic propositions : a deterministic transition function状态转移 is the initial state初始状态 : the set of accepting states状态转移后的后续状态 - Complete DFA: for every state
and for every input symbol the transition function is defined. 对于任意初始状态和action,总有后续状态 Incomplete DFA: can be made complete by introducing a sink state and directing all undefined transitions into the sink state.
- Transition system (TS):
, the interaction between the robot and its adversary, two-player turn based. : set of states partitioned on the basis of the turn of and : set of actions for and respectively. : the deterministic transition function. : a set of atomic propositions. : the labeling function
- Reactive game:
: transition function
5. [50%]Identifying stealthy attackers in a game theoretic framework using deception
Anjon Basak et al., AG 2019
5.1. 总结:
- 在Security game中,attacker会试图避免被发现或者被识别(detection and identification,表征为特定轨迹),尝试混淆自己和其它attacker的特征。从defender的角度,如何通过带有特定目的的optimizing defensive deception actions(例如如何设置honeypot)去尽早的识别特定的attacker。
- 相较于其它事后分析attacker的方法,通过attacker行动前对环境的设置以便于获取更多信息
- 一套关于proactive deception的framework:
- A multi-stage game theoretic model to strategically deploy honeypots to force the attacker to reveal his type early.
- Show case study
- Present a general model, a basic solution algorithm, and simulation results
5.2. 工作1:model (section4)
| 项目 | 解释 | |
| 环境/游戏类型 | 回合 | 单一回合 |
| 环境 | Node(state), value/cost, exploit(action), deterministic.(详情参见后续) | |
| Follower/attacker | 知识 | 知道整个网络拓朴,知道每个节点类型,但是不知道节点是否是由honeypot伪装而来 |
| 策略 | 多个attacker类型中的某一种(在game中不会变化) 抵达指定目的(某个特定state,或特定类型的state),且cost最低,轨迹尽可能与其它类型的attacker重合 | |
| Defender/leader | 知识 | 已知所有attacker类型,但是不知道具体是哪种 |
| 策略 | ||
- Node
, goal node (类比state) - Value and cost of a node, goal with high value(类比reward)
- Exploit
(edge between nodes)(类比action)。 - node-exploit-node与MDP的state-action-state的区别:
- Node
与 存在某种形式从 到 的连接(如某种网络拓扑),一个attacker具有一些exploit的能力 ,在 处可以执行某些exploit ,那么如果 ,则attacker可以通过执行任意 ,通过付出cost 到达 并获得在此处的reward (如果存在)。 即首先需要存在连接,其次需要有可执行(attacker和所在node同时具备)的exploit,才可能执行。 (一般网络攻防中应该是下一个node存在相应的exploit,不过从模型的角度理解效果是等价的) - State-action-state的连接中,一个action对应一条edge(一般来说),一般一个action去往不同的state
- Node
- N类attacker type(
),唯一defender - Attacker:
- Complete knowledge about the network(类比environment)
- Single deterministic policy
to reach the goal - Some exploits
- 无法区分一个node是否是honeypot
- Defender:
- 通过在environment中放置honeypot以deploy deception
- The configurations of the honeypots为:从real node T中随机选取(为什么随机选取?)
- Attacker:
- Game process:
- Start: attacker随机选取一个类型
- 第
回合:defender有从开始到 的所有历史作为参照。依据策略布置 个honeypot。attacker随时获知网络的更新并规划新的optimal plan。 若多组plan的cost相同,则attacker会选取其中have the maximum commom overlapping length的。 - End:attacker caught by the deception或者reaches to its goal node
- Start: attacker随机选取一个类型
- APT: advanced persistent threat高级长期威胁****
5.3. 工作2:Three case studies
5.3.1. Attackers with same exploits but different goals
| attacker | attacker | |
|---|---|---|
| exploits | ||
| goal | ||
| plan | 绿线 | 红线 |
- 添加了一个连接了
和 的decoy ,使得 直接在第一步时认为自己已经到达终点,区分了 和 。 - 否则将在第六步区分出
和 。 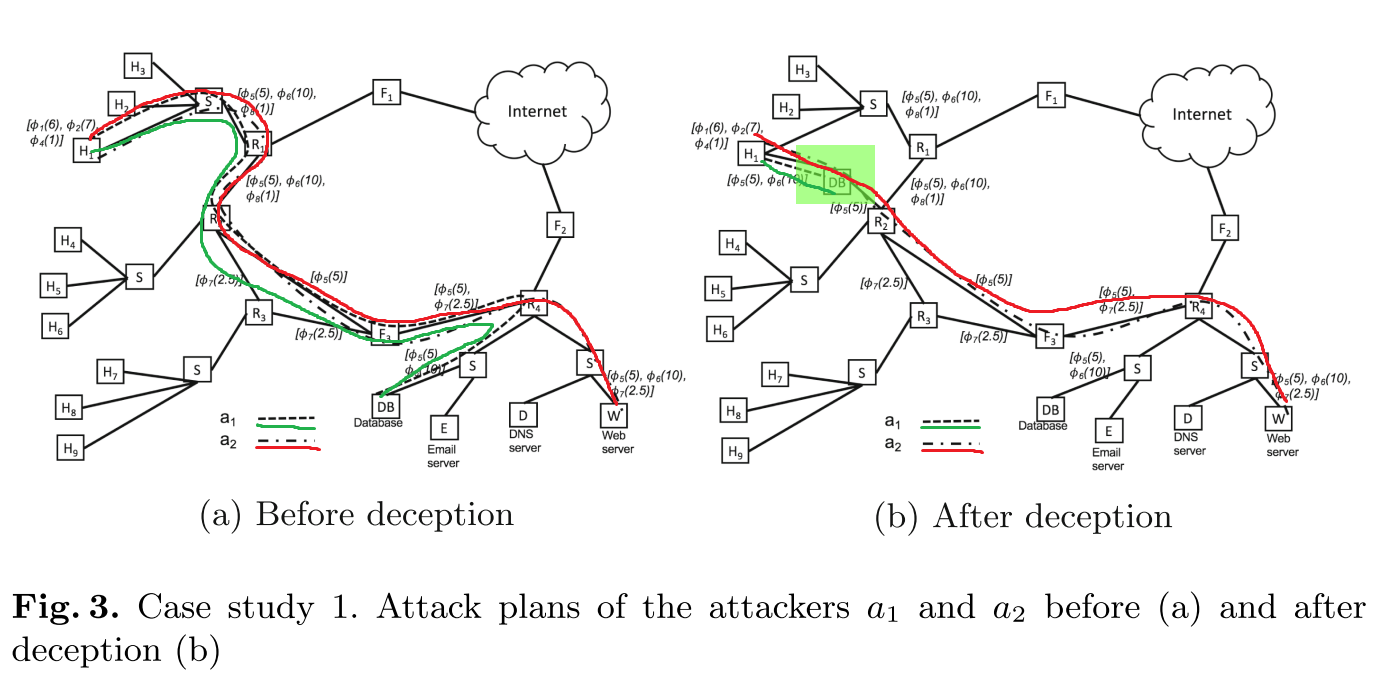
5.3.2. Attackers with shared exploits and different goals
| attacker | attacker | |
|---|---|---|
| exploits | ||
| goal | ||
| plan | 绿线 | 红线 |
- 添加了一个连接了
和 的decoy ,使得 认为从 到 到 的路径的代价比原路径小,区分了 和 。 - 否则将在第四步区分出
和 。 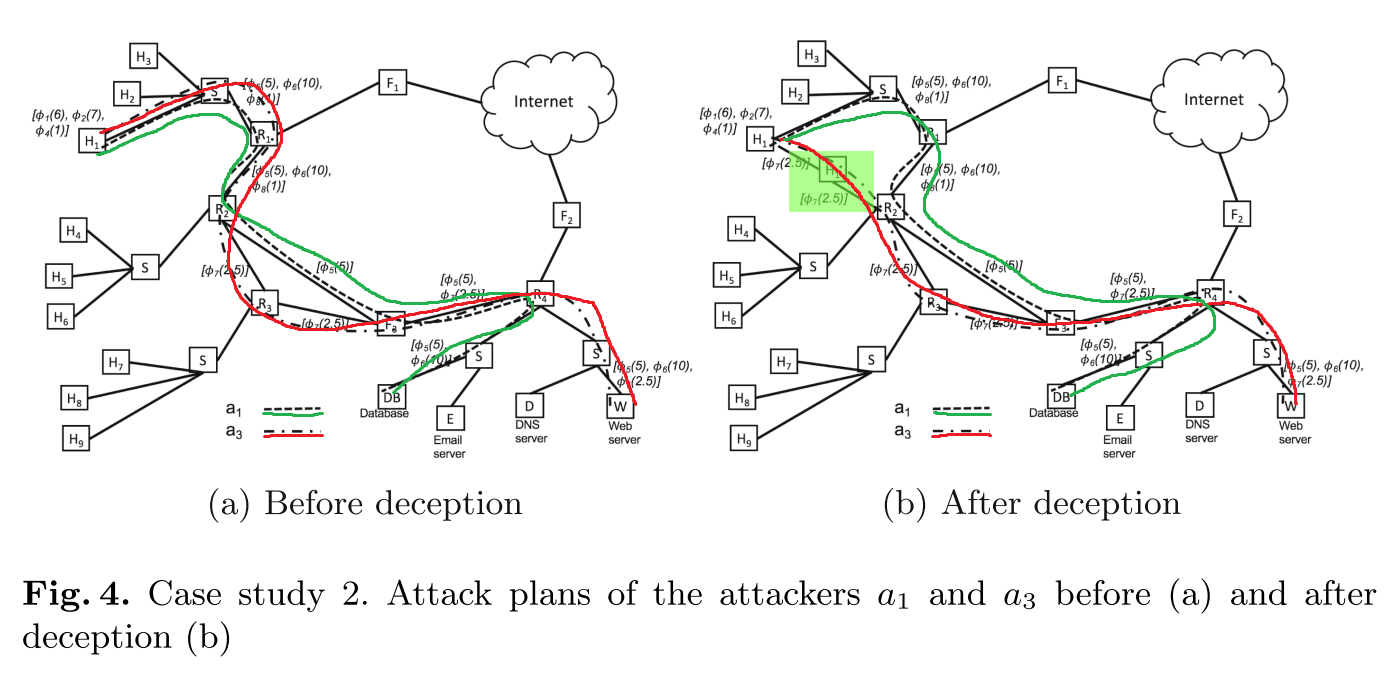
5.3.3. Attackers with shared exploits but same goals
| attacker | attacker | |
|---|---|---|
| exploits | ||
| goal | ||
| plan | 绿线 | 红线 |
- 添加了一个连接了
和 的decoy ,使得 认为经过 的路径的代价比原路径小,区分了 和 - 否则无法区分
和 。 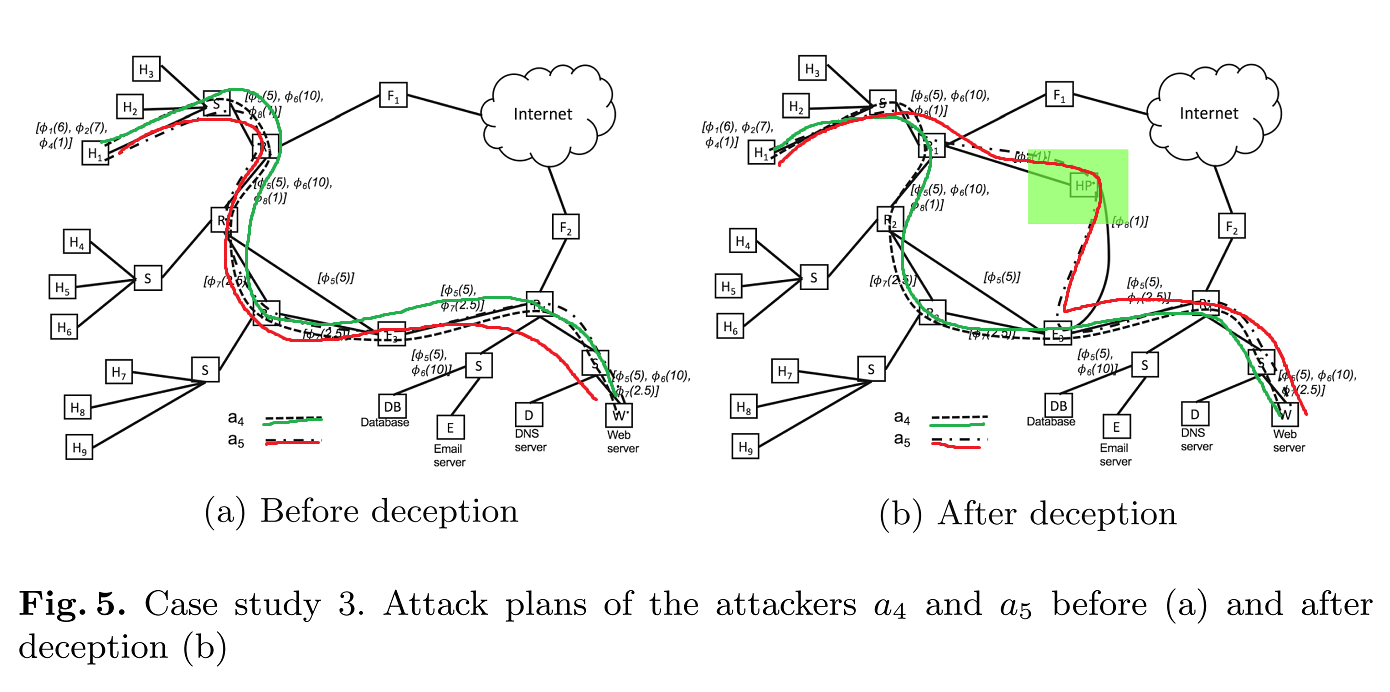
5.4. Defender’s and attacker’s deceison making
- 三组实验
- 不同 density of edges and shared vulnerablilities between nodes对defender何时能检测出attacker类型的影响
- Same edge density and shared vulnerabilities between nodes (fixed to 40%),attackers之间shared exploits不同
- 不同defender’s techniques:
- minimizing maximum overlap: min-max-overlap
- minimizing maximum expected overlap: min-max-exp-overlap
- minimizing entropy: min-entropy
- other possible reading probe design
6. [0%]A game-theoretic taxonomy and survey of defensive deception for cybersecurity and privacy
Jeffrey Pawlick et al., ACM computing surveys 2019