任务规划
GPT-4V(ision) for Robotics: Multimodal Task Planning from Human Demonstration
Naoki Wake et al., ArXiv2023, Microsoft Katsu’s group
- 整体分为两大部分,symbolic task planner和affordance analyzer
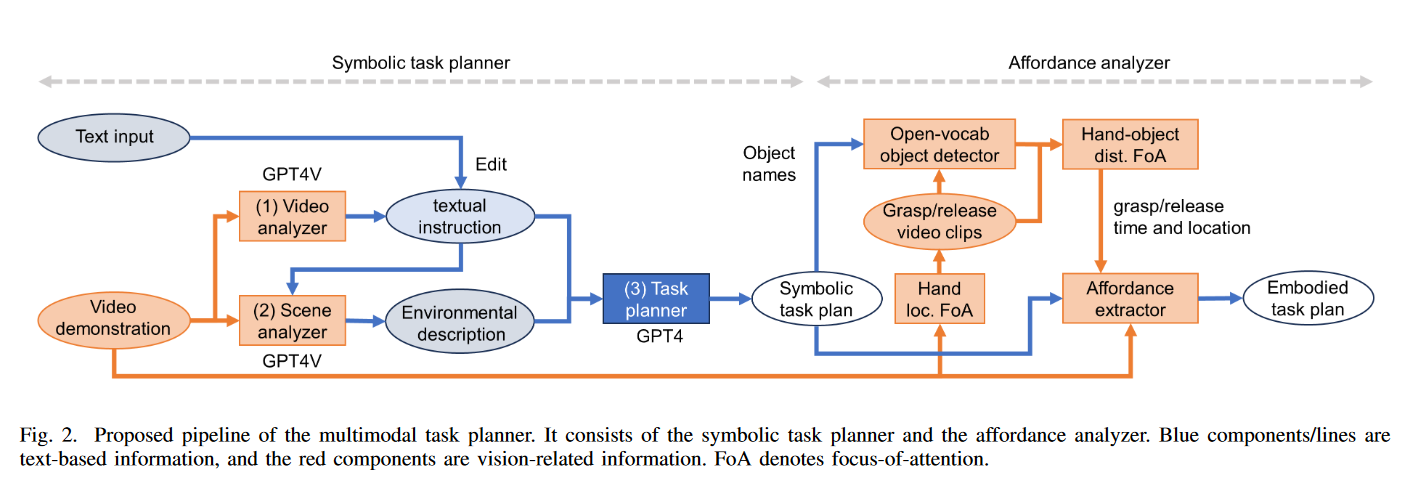
- Symbolic task planner
- 分为三个步骤(转化为三个组件):1)将视频转化为文字指令,2)辨识场景中物体及其属性,3)将指令转化为机器人任务描述。解决方法:设计GPT prompt。
- 三个组件分别为:
- video analysis,使用GPT-4V识别人的动作,转写(transcribes)为文字指令,并非直接逐帧输入,而是抽帧(regular intervals)

- scene analysis,使用GPT-4V通过第一帧和video analysis获取的文字指令,识别场景中的物体,是否可以抓取的属性和物体之间的空间关系。同时要求GPT输出文字解释

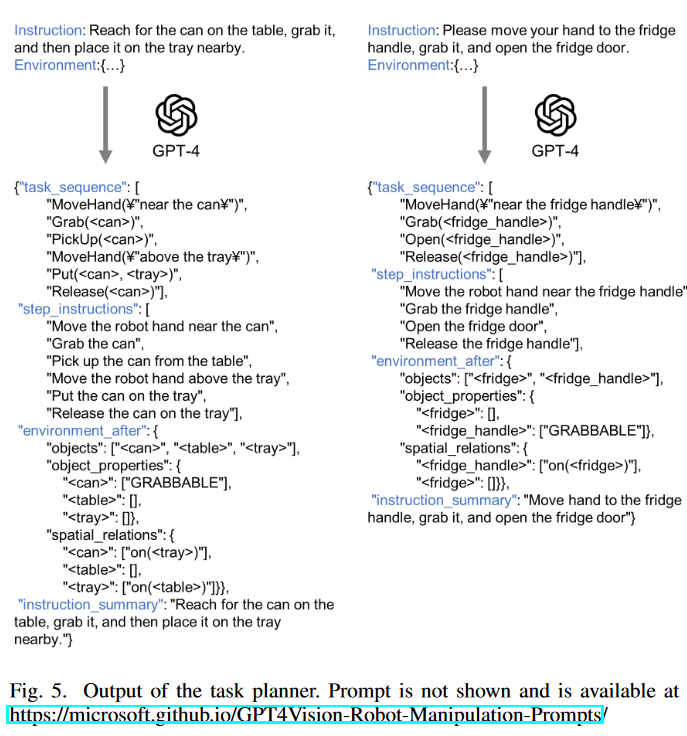
- task planning,使用GPT-4,将指令转化为机器人任务[10]
- N. Wake, A. Kanehira, K. Sasabuchi, J. Takamatsu, and K. Ikeuchi, “Chatgpt empowered long-step robot control in various environments: A case application,” IEEE Access, vol. 11, pp. 95060–95078, 2023.
- N. Wake, A. Kanehira, K. Sasabuchi, J. Takamatsu, and K. Ikeuchi, “Chatgpt empowered long-step robot control in various environments: A case application,” IEEE Access, vol. 11, pp. 95060–95078, 2023.
- video analysis,使用GPT-4V识别人的动作,转写(transcribes)为文字指令,并非直接逐帧输入,而是抽帧(regular intervals)
- Affordance analyzer
- 根据任务特性和物品名称,关注手与物体之间的关系
- 检测抓取和释放是在何时、何处发生的
- 分为三个组件:
- 检测人手的抓取和释放的注意力机制,抓握/释放事件是否发生?
使用基于YOLO训练的检测器
- 分析第一帧和最后一帧
- 手中没有握着东西->手中握着东西
- 手中握着东西->手中没有握东西
- 其他情况
- 分析第一帧和最后一帧
- 手与物体交互的注意力机制,检测抓取与释放的时空位置(spatiotemporal location)
使用开源的Detic
- 检测在何时抓握了何处,将视频与抓握/放下事件对齐
- 从对齐后的视频中提取可行性信息
参考之前的paper[50]
- 是否可以执行抓取、移动、释放、拾起、放下、旋转、滑动、在表面移动这八种任务。
- 检测人手的抓取和释放的注意力机制,抓握/释放事件是否发生?
使用基于YOLO训练的检测器
- 问题:
- 什么是task and motion planning (TAMP) [40]?
- C. R. Garrett, R. Chitnis, R. Holladay, B. Kim, T. Silver, L. P. Kaelbling, and T. Lozano-Pérez, “Integrated task and motion planning,” Annual review of control, robotics, and autonomous systems, vol. 4, pp. 265293, 2021.
- 什么是granularity of grasp-manipulation-release [50]?[51]是什么?
- N. Wake, R. Arakawa, I. Yanokura, T. Kiyokawa, K. Sasabuchi, J. Takamatsu, and K. Ikeuchi, “A learning-from-observation framework: One-shot robot teaching for grasp-manipulation-release household operations,” in 2021 IEEE/SICE International Symposium on System Integration (SII), IEEE, 2021.
- K. Ikeuchi, N. Wake, R. Arakawa, K. Sasabuchi, and J. Takamatsu, “Semantic constraints to represent common sense required in household actions for multi-modal learning-from-observation robot,” arXiv preprint arXiv:2103.02201, 2021.
- 什么是Kuhn-Tucker theory [52]?
- H. T. Kuhn and W. L. Inequalities, “Related systems,” Annals of Mathematic Studies, Princeton Univ. Press. EEUU, 1956.
- 什么是task and motion planning (TAMP) [40]?