Vision Language Models
2024
SpatialBot: Precise Spatial Understanding with Vision Language Models
Wenxiao Cai et al., Shanghai Jiao Tong University, ArXiv, 2024
- VQA:Visual Question Answering,ICCV2015的论文
- 输入为RGB-D,创造了个SpatialQA数据集(large-scale RGB-D VQA dataset),用以训练SpatialBot,并用Spatial Bench来评估VLM对空间理解的性能
- SpatialBot的核心是什么?原理是什么?给出什么样的输出?
- Monocular Depth Estimation (MDE)
- 输入为RGB和深度图,通过使用MDE,从彩色图像估计深度图像,并于深度图像进行验证
estimating depth images from RGB images using MDE, unifying the format of depth images, generating basic VQAs for VLM training, and generating depth related VQAs - 输出:三个层次
- Low-Level
- point depth,图中某一点的距离值,直接从depth map中取样
- Depth Description and Analysis,对深度图进行描述
- Middel-Level
- RGB-D alignment、object depth,某个物体的测量距离值
- Proximity Relationships,哪个更近?哪个更远?
- High-Level
- Counting and Enumeration
- Spatial Relationship Understanding:左右关系、远近关系
- Low-Level
- SpatialBot系统设计
- 深度图编码
- 模型使用标准VLM(
standard VLM)- VLM使用Bunny,LLM基底为Phi-2-3B,Phi-3-4B(微软),QWen-1.5-4B(阿里通义千问)和Llama-3-8B,图像使用SigLIP编码
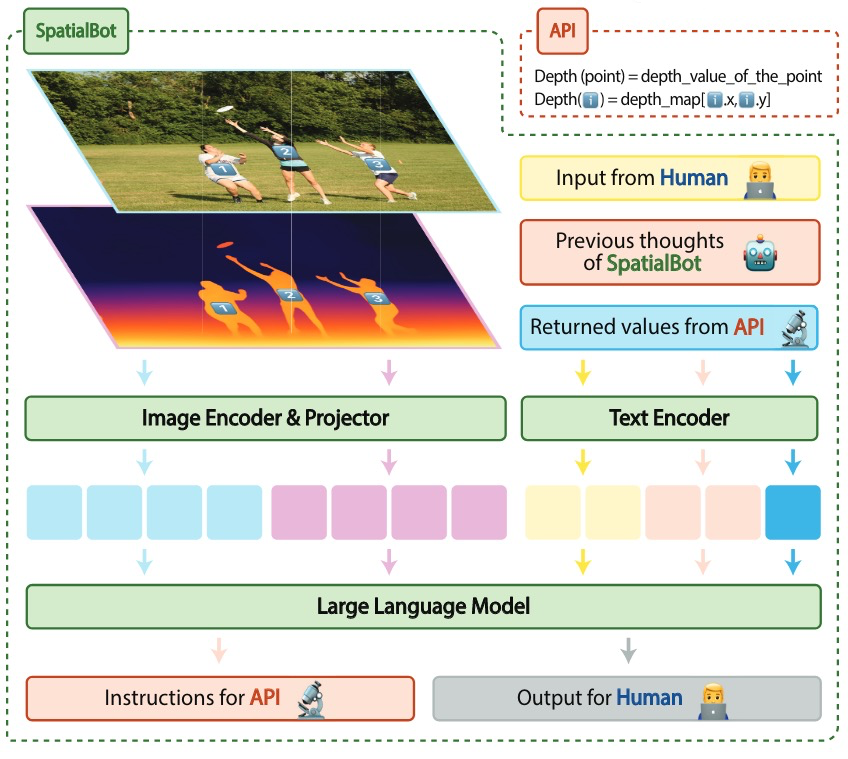
- VLM使用Bunny,LLM基底为Phi-2-3B,Phi-3-4B(微软),QWen-1.5-4B(阿里通义千问)和Llama-3-8B,图像使用SigLIP编码
- SpatialQA-E (Embodiment task):
- 输出为一个长度为7的向量,其元素为end-effector的7个自由度(6个空间自由度+上夹爪张开闭合),移动的变量从0到1之间,以0.01间隔取值
- QWen-1.5-0.5B作为LLM基底,CLIP作为vision encoder用于机械臂的操作任务(pick and place)